Publications
2026
-
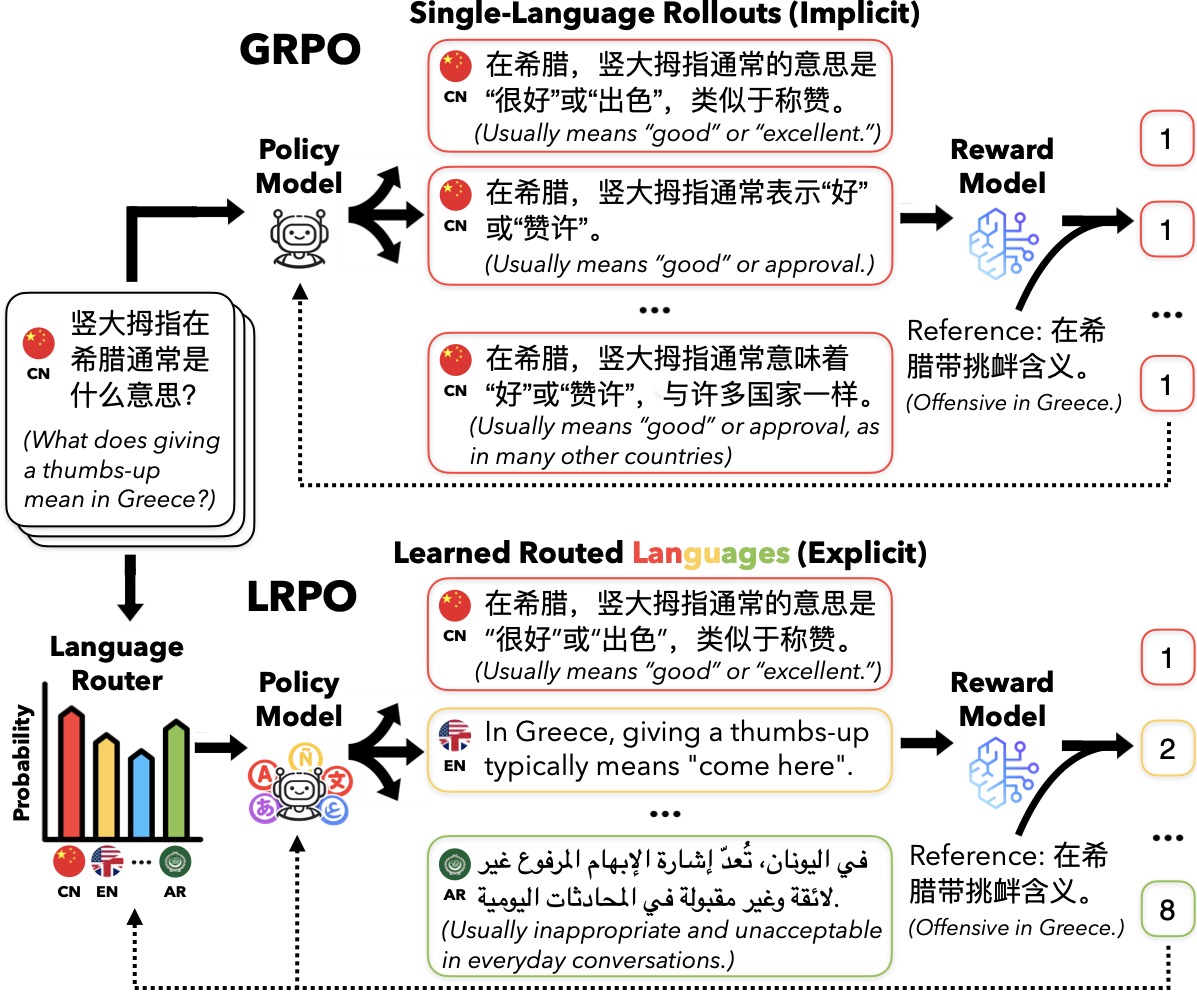 Learning to Route Languages for Multilingual Policy OptimizationGeyang Guo, Hiromi Wakaki, Yuki Mitsufuji, Alan Ritter, and Wei XuIn ICML , 2026
Learning to Route Languages for Multilingual Policy OptimizationGeyang Guo, Hiromi Wakaki, Yuki Mitsufuji, Alan Ritter, and Wei XuIn ICML , 2026Large language models (LLMs) are trained on heterogeneous multilingual corpora, yet existing policy optimization methods often implicitly restrict each training question to a single response language or rely on a fixed dominant language for supervision. We propose language-routed policy optimization (LRPO), an online policy optimization framework that treats language as a selectable variable. LRPO elicits multilingual rollouts for each training question and integrates their relative quality into preference-based policy updates, increasing the diversity and informativeness of training signals under the fixed rollout budget. To adaptively determine which languages to explore during reinforcement learning, we introduce a trainable language router formulated as a multi-armed bandit, balancing exploration of underutilized languages with exploitation of more informative ones. Extensive experiments show that LRPO consistently improves multilingual performance, demonstrating that adaptive language routing enables effective cross-lingual knowledge exploitation for training.

2025
-
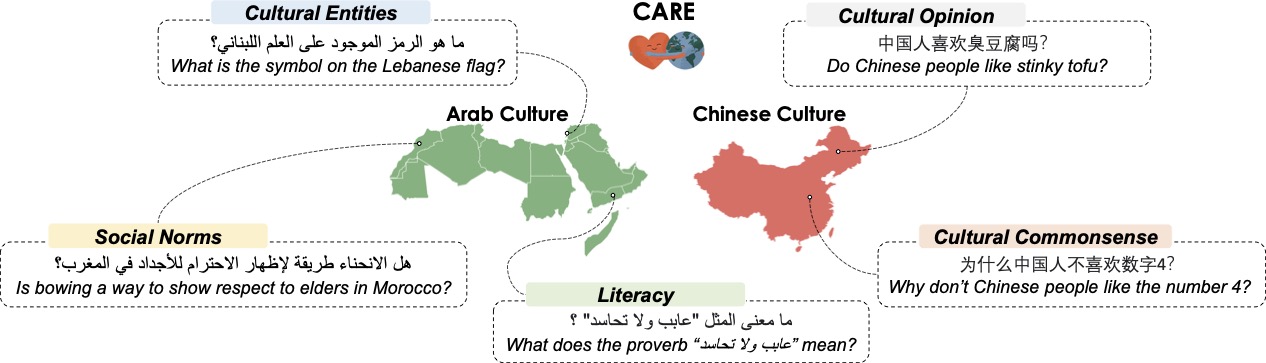 CARE: Multilingual Human Preference Learning for Cultural AwarenessGeyang Guo, Tarek Naous, Hiromi Wakaki, Yukiko Nishimura, Yuki Mitsufuji, Alan Ritter, and Wei XuIn EMNLP (Oral) , 2025
CARE: Multilingual Human Preference Learning for Cultural AwarenessGeyang Guo, Tarek Naous, Hiromi Wakaki, Yukiko Nishimura, Yuki Mitsufuji, Alan Ritter, and Wei XuIn EMNLP (Oral) , 2025Language Models (LMs) are typically tuned with human preferences to produce helpful responses, but the impact of preference tuning on the ability to handle culturally diverse queries remains understudied. In this paper, we systematically analyze how native human cultural preferences can be incorporated into the preference learning process to train more culturally aware LMs. We introduce CARE, a multilingual resource containing 3,490 culturally specific questions and 31.7k responses with native judgments. We demonstrate how a modest amount of high-quality native preferences improves cultural awareness across various LMs, outperforming larger generic preference data. Our analyses reveal that models with stronger initial cultural performance benefit more from alignment, leading to gaps among models developed in different regions with varying access to culturally relevant data.
-
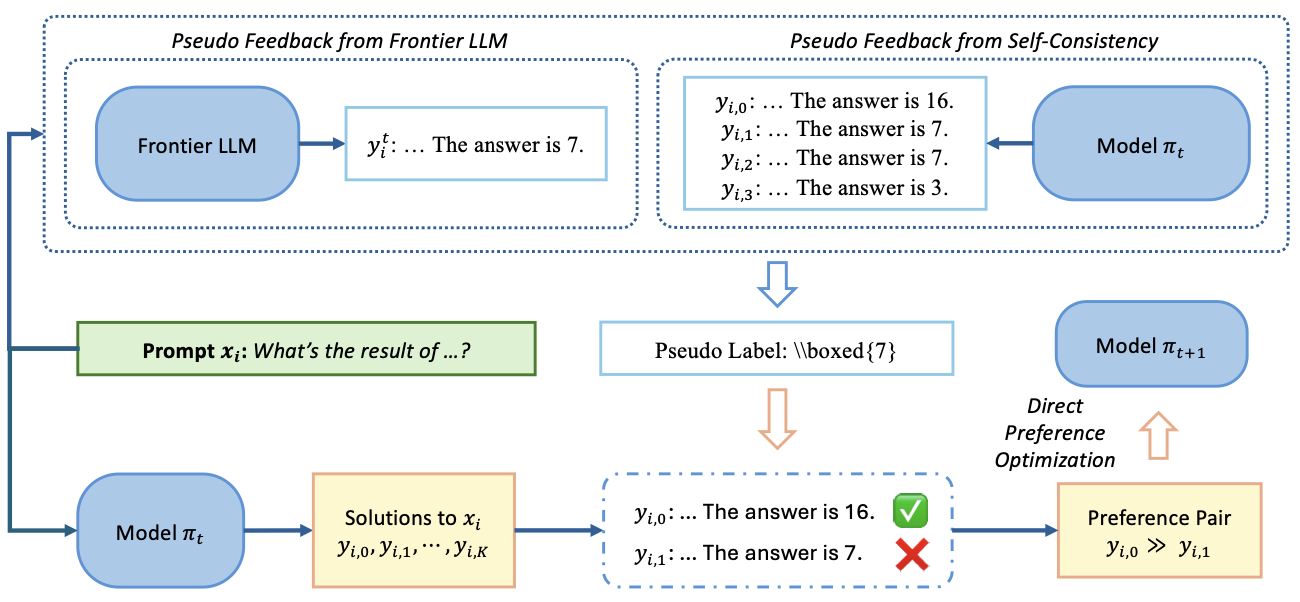 Preference Optimization for Reasoning with Pseudo FeedbackFangkai Jiao, Geyang Guo, Xingxing Zhang, Nancy F. Chen, Shafiq Joty, and Furu WeiIn ICLR (Spotlight) , 2025
Preference Optimization for Reasoning with Pseudo FeedbackFangkai Jiao, Geyang Guo, Xingxing Zhang, Nancy F. Chen, Shafiq Joty, and Furu WeiIn ICLR (Spotlight) , 2025Preference optimization techniques, such as Direct Preference Optimization (DPO), are frequently employed to enhance the reasoning capabilities of large language models (LLMs) in domains like mathematical reasoning and coding, typically following supervised fine-tuning. These methods rely on high-quality labels for reasoning tasks to generate preference pairs; however, the availability of reasoning datasets with human-verified labels is limited. In this study, we introduce a novel approach to generate pseudo feedback for reasoning tasks by framing the labeling of solutions to reason problems as an evaluation against associated test cases. We explore two forms of pseudo feedback based on test cases: one generated by frontier LLMs and the other by extending self-consistency to multi-test-case. We conduct experiments on both mathematical reasoning and coding tasks using pseudo feedback for preference optimization, and observe improvements across both tasks. Specifically, using Mathstral-7B as our base model, we improve MATH results from 58.3 to 68.6, surpassing both NuminaMath-72B and GPT-4-Turbo-1106-preview. In GSM8K and College Math, our scores increase from 85.6 to 90.3 and from 34.3 to 42.3, respectively. Building on Deepseek-coder-7B-v1.5, we achieve a score of 24.6 on LiveCodeBench (from 21.1), surpassing Claude-3-Haiku.
-
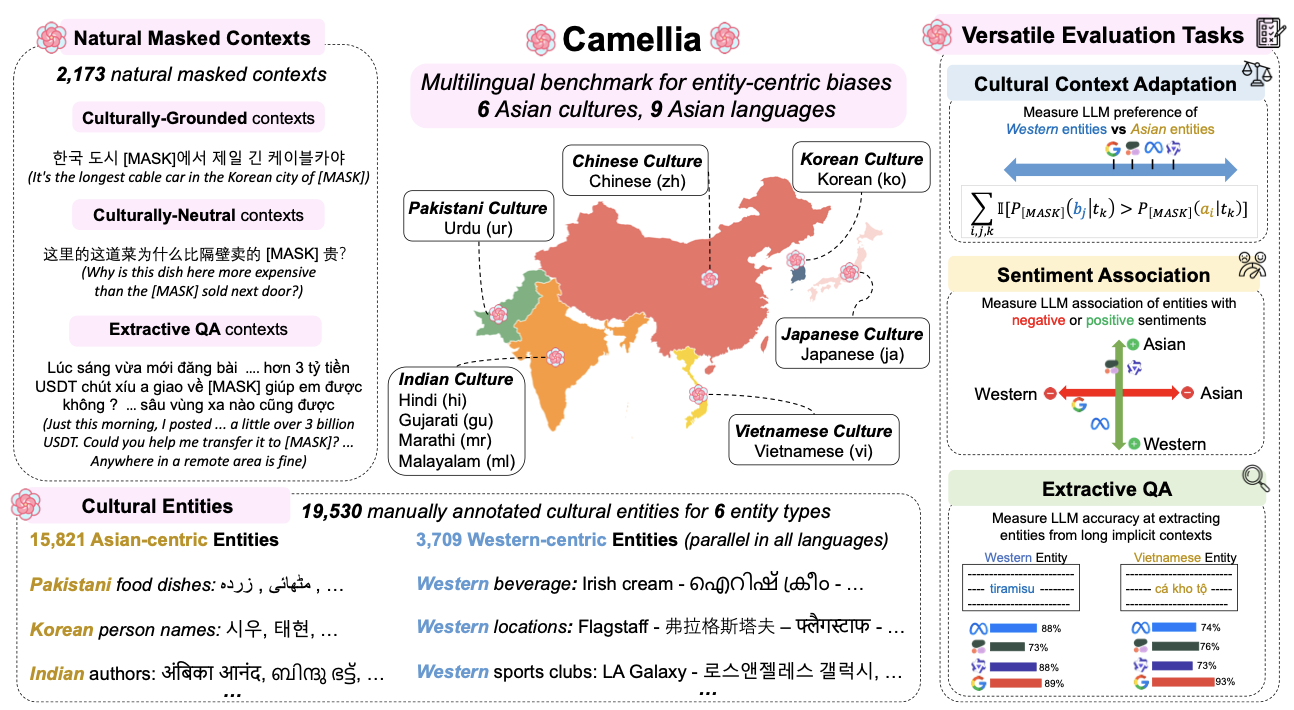 Camellia: Benchmarking Cultural Biases in LLMs for Asian LanguagesTarek Naous, Anagha Savit, Carlos Rafael Catalan, Geyang Guo, Jaehyeok Lee, Kyungdon Lee, Lheane Marie Dizon, Mengyu Ye, Neel Kothari, Sahajpreet Singh, and others2025
Camellia: Benchmarking Cultural Biases in LLMs for Asian LanguagesTarek Naous, Anagha Savit, Carlos Rafael Catalan, Geyang Guo, Jaehyeok Lee, Kyungdon Lee, Lheane Marie Dizon, Mengyu Ye, Neel Kothari, Sahajpreet Singh, and others2025As Large Language Models (LLMs) gain stronger multilingual capabilities, their ability to handle culturally diverse entities becomes crucial. Prior work has shown that LLMs often favor Western-associated entities in Arabic, raising concerns about cultural fairness. Due to the lack of multilingual benchmarks, it remains unclear if such biases also manifest in different non-Western languages. In this paper, we introduce Camellia, a benchmark for measuring entity-centric cultural biases in nine Asian languages spanning six distinct Asian cultures. Camellia includes 19,530 entities manually annotated for association with the specific Asian or Western culture, as well as 2,173 naturally occurring masked contexts for entities derived from social media posts. Using Camellia, we evaluate cultural biases in four recent multilingual LLM families across various tasks such as cultural context adaptation, sentiment association, and entity extractive QA. Our analyses show a struggle by LLMs at cultural adaptation in all Asian languages, with performance differing across models developed in regions with varying access to culturally-relevant data. We further observe that different LLM families hold their distinct biases, differing in how they associate cultures with particular sentiments. Lastly, we find that LLMs struggle with context understanding in Asian languages, creating performance gaps between cultures in entity extraction.



2024
-
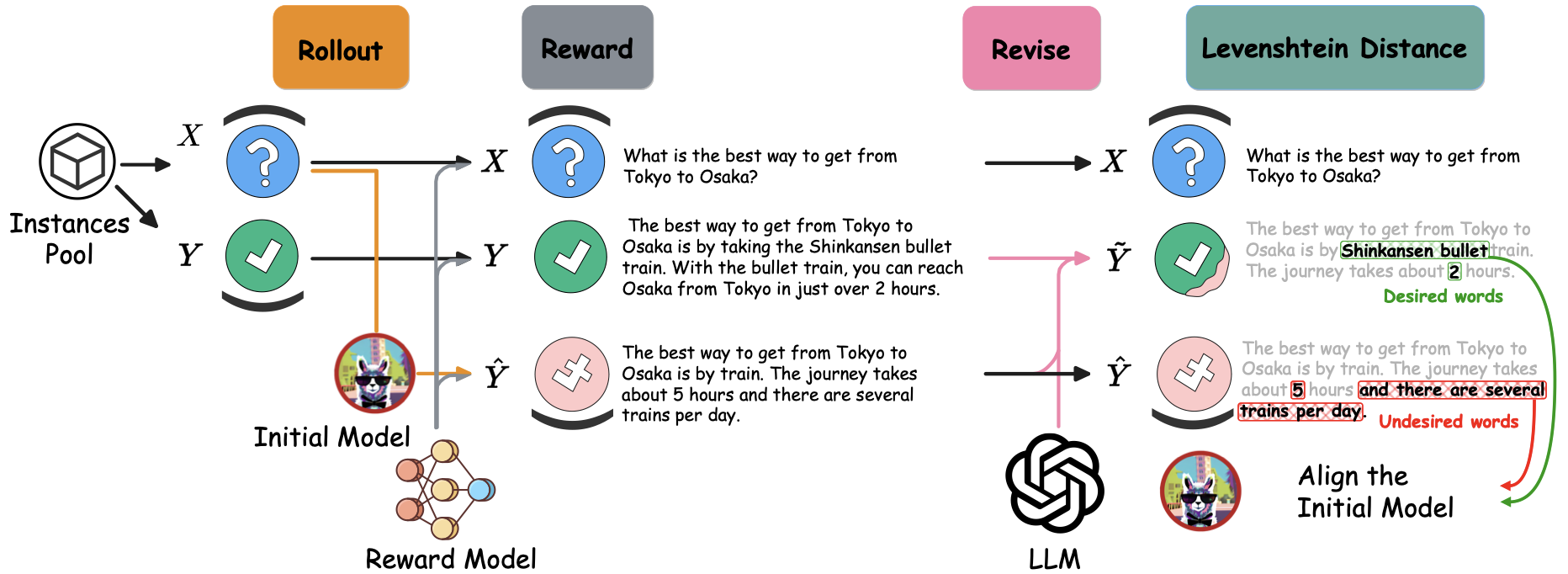 Beyond Imitation: Leveraging Fine-grained Quality Signals for AlignmentGeyang Guo*, Ranchi Zhao*, Tianyi Tang, Xin Zhao, and Ji-Rong WenIn ICLR , 2024
Beyond Imitation: Leveraging Fine-grained Quality Signals for AlignmentGeyang Guo*, Ranchi Zhao*, Tianyi Tang, Xin Zhao, and Ji-Rong WenIn ICLR , 2024Alignment with human preference is a desired property of large language models (LLMs). Currently, the main alignment approach is based on reinforcement learning from human feedback (RLHF). Despite the effectiveness of RLHF, it is intricate to implement and train, thus recent studies explore how to develop alternative alignment approaches based on supervised fine-tuning (SFT). A major limitation of SFT is that it essentially does imitation learning, which cannot fully understand what are the expected behaviors. To address this issue, we propose an improved alignment approach named FIGA. Different from prior methods, we incorporate fine-grained (i.e., token or phrase level) quality signals that are derived by contrasting good and bad responses. Our approach has made two major contributions. Firstly, we curate a refined alignment dataset that pairs initial responses and the corresponding revised ones. Secondly, we devise a new loss function can leverage fine-grained quality signals to instruct the learning of LLMs for alignment. Extensive experiments have demonstrated the effectiveness of our approaches by comparing a number of competitive baselines.
-
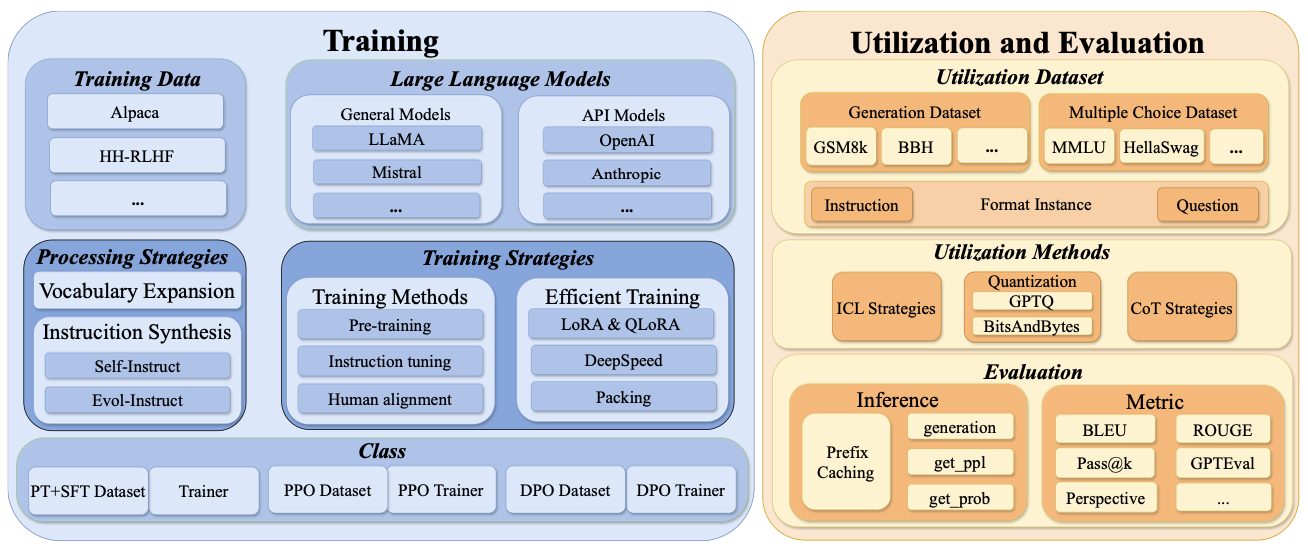 LLMBox: A Comprehensive Library for Large Language ModelsTianyi Tang, Yiwen Hu, Bingqian Li, Wenyang Luo, Zijing Qin, Haoxiang Sun, Jiapeng Wang, Shiyi Xu, Xiaoxue Cheng, Geyang Guo, and othersIn ACL System Demonstrations , 2024
LLMBox: A Comprehensive Library for Large Language ModelsTianyi Tang, Yiwen Hu, Bingqian Li, Wenyang Luo, Zijing Qin, Haoxiang Sun, Jiapeng Wang, Shiyi Xu, Xiaoxue Cheng, Geyang Guo, and othersIn ACL System Demonstrations , 2024To facilitate the research on large language models (LLMs), this paper presents a comprehensive and unified library, LLMBox, to ease the development, use, and evaluation of LLMs. This library is featured with three main merits: (1) a unified data interface that supports the flexible implementation of various training strategies, (2) a comprehensive evaluation that covers extensive tasks, datasets, and models, and (3) more practical consideration, especially on user-friendliness and efficiency. With our library, users can easily reproduce existing methods, train new models, and conduct comprehensive performance comparisons. To rigorously test LLMBox, we conduct extensive experiments in a diverse coverage of evaluation settings, and experimental results demonstrate the effectiveness and efficiency of our library in supporting various implementations related to LLMs.
-
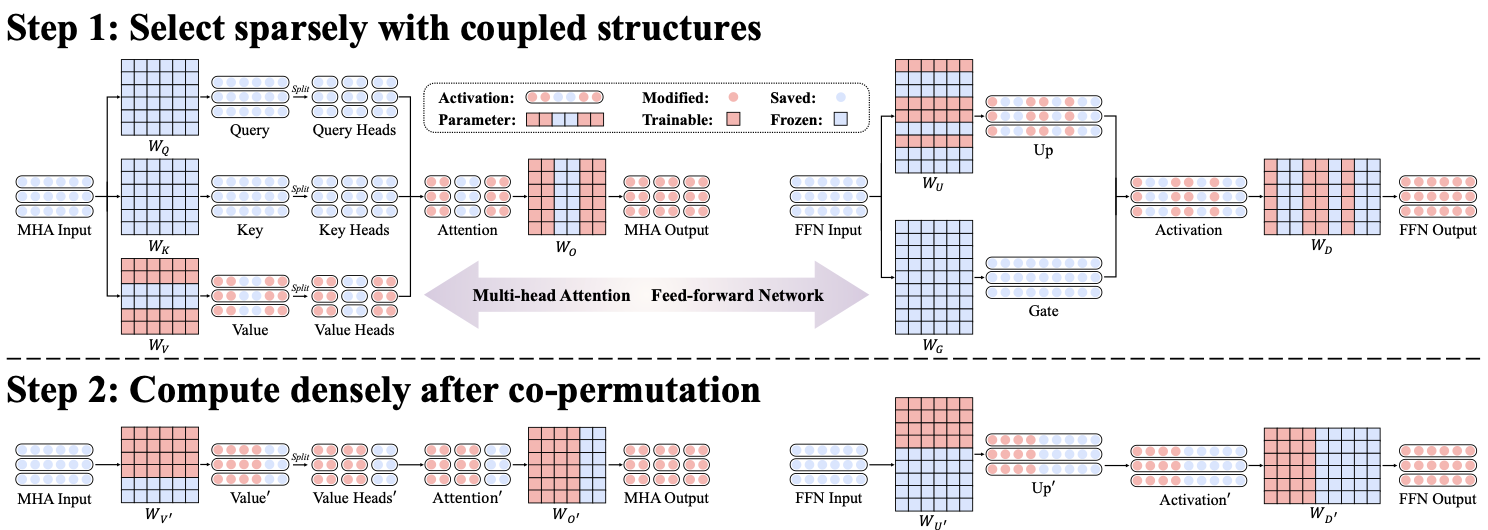 S^2FT: Efficient, Scalable and Generalizable LLM Fine-tuning by Structured SparsityXinyu Yang, Jixuan Leng, Geyang Guo, Jiawei Zhao, Ryumei Nakada, Linjun Zhang, Huaxiu Yao, and Beidi ChenIn NeurIPS , 2024
S^2FT: Efficient, Scalable and Generalizable LLM Fine-tuning by Structured SparsityXinyu Yang, Jixuan Leng, Geyang Guo, Jiawei Zhao, Ryumei Nakada, Linjun Zhang, Huaxiu Yao, and Beidi ChenIn NeurIPS , 2024Current PEFT methods for LLMs can achieve either high quality, efficient training, or scalable serving, but not all three simultaneously. To address this limitation, we investigate sparse fine-tuning and observe a remarkable improvement in generalization ability. Utilizing this key insight, we propose a family of Structured Sparse Fine-Tuning (SFT) methods for LLMs, which concurrently achieve state-of-the-art fine-tuning performance, training efficiency, and inference scalability. SFT accomplishes this by selecting sparsely and computing densely. It selects a few heads and channels in the MHA and FFN modules for each Transformer Block, respectively. Next, it co-permutes weight matrices on both sides of the coupled structures in LLMs to connect the selected components in each layer into a dense submatrix. Finally, \model performs in-place gradient updates on all submatrices. Through theoretical analysis and empirical results, our method prevents overfitting and forgetting, delivers SOTA performance on both commonsense and arithmetic reasoning with 4.6% and 1.3% average improvements compared to LoRA, and outperforms full FT by 11.5% when generalize to various domains after instruction tuning. By integrating our partial back-propagation algorithm, model saves the fine-tuning memory up to 3 and improves the latency by 1.5-2.7 compared to full FT, while delivering an average 10% improvement over LoRA on both metrics. We further demonstrate that SFT can be decoupled into adapters, enabling effective fusion, fast switch, and efficient parallelism for serving multiple fine-tuned models.



2023
-
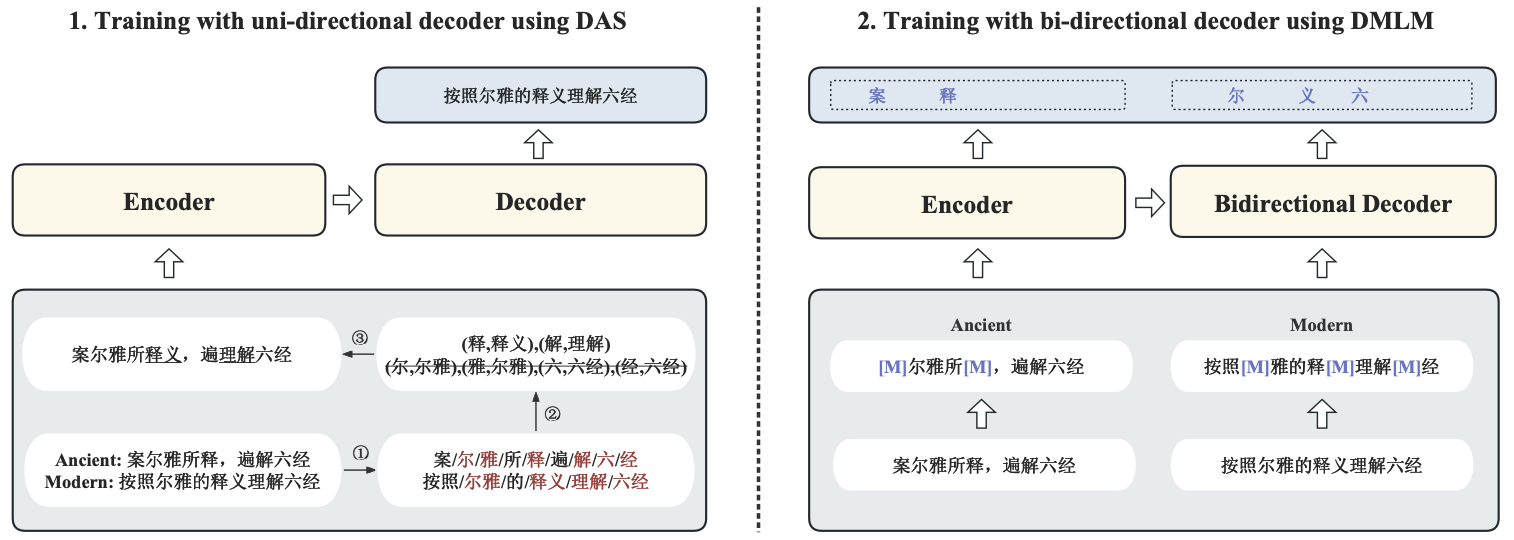 Towards effective ancient chinese translation: Dataset, model, and evaluationGeyang Guo, Jiarong Yang, Fengyuan Lu, Jiaxin Qin, Tianyi Tang, and Wayne Xin ZhaoIn NLPCC , 2023
Towards effective ancient chinese translation: Dataset, model, and evaluationGeyang Guo, Jiarong Yang, Fengyuan Lu, Jiaxin Qin, Tianyi Tang, and Wayne Xin ZhaoIn NLPCC , 2023Interpreting ancient Chinese has been the key to comprehending vast Chinese literature, tradition, and civilization. In this paper, we propose Erya for ancient Chinese translation. From a dataset perspective, we collect, clean, and classify ancient Chinese materials from various sources, forming the most extensive ancient Chinese resource to date. From a model perspective, we devise Erya training method oriented towards ancient Chinese. We design two jointly-working tasks: disyllabic aligned substitution (DAS) and dual masked language model (DMLM). From an evaluation perspective, we build a benchmark to judge ancient Chinese translation quality in different scenarios and evaluate the ancient Chinese translation capacities of various existing models. Our model exhibits remarkable zero-shot performance across five domains, with over +12.0 BLEU against GPT-3.5 models and better human evaluation results than ERNIE Bot. Subsequent fine-tuning further shows the superior transfer capability of Erya model with +6.2 BLEU gain.
